Les robots sont maintenant majoritaires sur le web
| Auteur | Message |
|---|---|
|
Dans le précédent message, dire que aucun blocage supplémentaire n’avait été ajouté, est à la fois vrai et faux. Aucun blocage d’IP n’a été ajouté, mais, et sans savoir si c’est une coïncide ou une cause, le fichier robots.txt a été modifié. Il a été ajouté la ligne “ Content-Signal: search=yes, ai-train=no, ai-input=no ” autant pour les robots « bloqués » que pour les robots non‑bloqués. C’était sans trop y croire, comme beaucoup de robots n’ont pas la politesse de tenir compte de robots.txt, ou seulement quand ça les arrange ou en jouant aux filous. La directive Content-Signal est une proposition de Cloudflare : contentsignals.org et Cloudflare offers way to block AI Overviews – will Google comply? (searchengineland.com), 24 Septembre 2025. Mais l’oligopole Google, ignore volontairement cette directive : Google Search Console regarding Cloudflare’s Content Signals: “Rule Ignored by Googlebot” (go-seo.com), 7 Mai 2026.
Ci‑dessous, le “ # ... ” est pour dire que des choses ont été éludées, pour raccourcir. Il n’y a pas que les robots des IAs qui sont bloqués, d’autres aussi, pour d’autres raisons. Code :User-agent: AhrefsBot Le ligne peut paraître sans objet pour les robots bloqués, mais c’est pour le notifier quand‑même et c’est aussi au cas où ils tiennent compte de cette indication même si c’est en ignorant l’interdiction d’aspirer le forum. Les jours prochains diront si c’est lié ou pas. En tous les cas, ils se sont tous arrêté en même temps, ou presque et c’est intriguant. — Édit de 23h10 — Comme indiqué dans l’édit du message précédent, c’était une fausse bonne nouvelle, c’est à nouveau reparti ")
|
|
|
Un bon site d’information sur les robots qui s’identifient : crawlercheck.com/directory. C’est une page du site, qui fournit d’autres services, mais c’est celui‑ci qui intéresse dans ce contexte. Les robots qui se masquent ne peuvent être reconnus que par leurs IPs et cette page n’en parle pas.
|
|
|
Une conséquence des abus des robots sur le forum :
Citation : Désolé, mais le forum est temporairement indisponible, réessayez dans quelques minutes. Ce message peut s’afficher parfois, il suffit souvent de re‑essayer quelques secondes après et ça remarche, mais le problème existe quand‑même, et ce n’est pas du tout normal pour un forum qui a entre deux et cinq visites (ou moins) par jour seulement. |
|
|
Mettre les choses sous forme de graphique, aide à y voir bien mieux qu’avec des trop longues listes de nombres, mais ça n’éclaire pas assez utilement pour le moment (comme connaître assez bien le phénomène pour y remédier).
C’est chaotique, il n’y a pas de régularité, s’il y a des raisons, elles sont inaccessibles aux gens qui ne sont pas de leur milieux. Les sursauts d’acharnement des robots sont autant soudains, en pente verticale, qu’ils n’ont pas de schéma qui se répète. 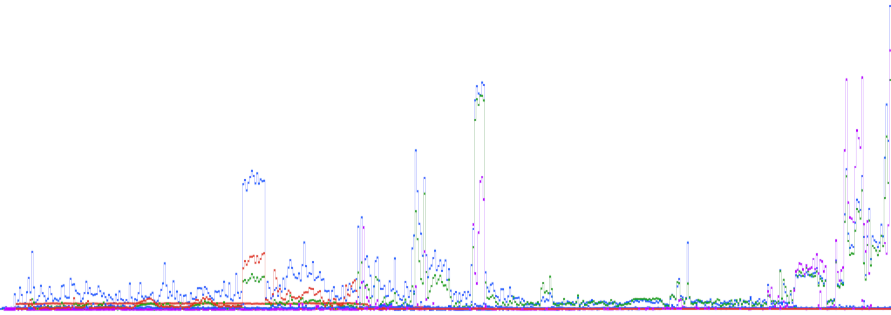 Tout à gauche, c’est environ début Janvier 2025, tout à droite, c’est hier, c’est un interval d’un an et demi (pas possible de faire plus, les données ont été perdues). Les couleurs représentent les status, c’est à dire OK, erreur, requête rejetée, à la peine, etc. L’image a été compressée en largeur, sinon elle était trop grande, mais on devine malgré le trait faible, que hier était le pire depuis un an et demi (et aussi depuis n’importe quand avant) et le bilan d’aujourd’hui sera encore pire que celui d’hier. Au milieu de tout ça, le peu d’humains qu’il y a, sont des poussières microscopiques, sans exagérer. Ce n’est pas une illusion, il y a effectivement beaucoup d’erreur 503 en ce moment, ce qui signifie que le serveur a des difficultés à suivre la cadence. Les jours où il y en a, il y en, les erreurs 503 sont pas loin d’être autant fréquente que les status 200. Ce n’est heureusement pas tous les jours comme ça, mais sur toute la période de un and et demi, le nombre d’erreur 503 est entre 9 et 10% du nombre de status 200, ce qui est vraiment beaucoup, au sens de beaucoup trop. Ce n’est pas un effondrement, mais c’est quand‑même une catastrophe. Tout ça pour des robots qui s’acharnent on ne sait même pas pour faire quoi de ce qu’ils siphonnent et en tous les cas, qui ne n’amènent pas de visites vers ici, ou très peu. Depuis la folie des IA qui a apparemment commencé en 2023 (je n’en étais pas du tout conscient et remettait sans cesse certaines choses à plus tard), la fréquentation du forum a vraiment beaucoup diminué. Il n’est pas certain que ce soit la cause, mais c’est suspect, surtout qu’un des buts des créateurs des IA, est de ne renvoyer les gens que le moins possible vers les sites, qui sont siphonnés au mépris de l’accord ou pas des gens qui les maintiennent. — Édit du 2026-06-12 — Ils sont environ 2600 en permanence sur le forum depuis toute la journée et aucune idée de ce qu’ils y font. Ils s’acharnent tellement qu’ils auraient dut tout indexer depuis longtemps déjà. Ça n’a aucun sens. Et plus les jours passent, plus ça semble s’aggraver, leur présence semble de plus en plus permanente. |
|
|
Voir aussi ce message en rapport : Re: Les intelligences artificielles (en général).
|
|
|
Citation : Cloudflare prévoit que le trafic bot dépassera le trafic humain d’ici fin 2029, et qu’en 2031, l’activité des bots dépassera à elle seule la totalité du trafic internet actuel. […], l’ampleur du phénomène justifie des mécanismes de contrôle beaucoup plus robustes que le robots.txt historique. Cloudflare défie Google avec une refonte majeure de robots.txt : la Content Signals Policy (neper.fr), Philippe Yonnet, 8 Octobre 2025. |
|
|
Une chose est étrange. Les requête provenant de googleusercontent.com (d’après la commande host sur les IPs), représentent à elles‑seules au minimum 6% des requêtes reçues par le forum, ce qui est beaucoup pour un forum qui est submergé.
On peut apprendre ceci à propos de ce domaine : Citation : Outils et fonctions produit dans lesquels l'utilisateur final déclenche une extraction. Par exemple, Google Site Verifier agit à la demande d'un utilisateur. Étant donné que l'exploration a été demandée par un utilisateur, ces outils ignorent les règles du fichier robots.txt. […] D’après : Validation des requêtes des robots d'exploration et des extracteurs Google (google.com). Ce n’est pas le robot d’exploration de Google, même pas celui des IAs et ces requêtes ignorent le robots.txt, qui est ignoré par trop de robots. D’autres gens se posent des questions à propos de ces requêtes qui sont en grand nombre. Il semble confirmé que le domaine appartient à Google, mais que ce qui y est fait, n’est pas pour le compte de Google. C’est douteux. |